Introduction
Modern software development increasingly relies on machine learning capabilities directly inside core products. Organizations face a critical architectural choice between local inference models or cloud-based endpoints when they deploy an artificial intelligence api. Companies rapidly adopt these technologies. Menlo Ventures reports that enterprises spent $37 billion on generative AI in 2025, and this amount represents a large increase from the previous year.
Despite this large investment, engineering teams often find it difficult to build sustainable architectures. A poor deployment model during the initial development phase leads to technical debt, regulatory compliance failures, or high scaling costs. Organizations evaluate specific workload requirements before they commit to a permanent infrastructure strategy. The next sections analyze the fundamental differences between cloud and local deployments to help development teams build resilient, cost-effective, and compliant systems.
Artificial Intelligence API Architectural Dilemma
The decision to integrate an artificial intelligence api creates a fundamental architectural dilemma between convenience and data control. Companies must choose between highly scalable cloud endpoints and sovereign local models. Cloud endpoints offer immediate access to computing capabilities and do not require upfront hardware investments. This convenience explains why organizations purchase 76% of enterprise use cases and do not build them internally. However, third-party endpoints require companies to send sensitive data outside the corporate perimeter.
If companies process proprietary information through external services, they lose absolute control over their data. This loss of control introduces severe compliance risks for healthcare and financial institutions. Local deployment solves this privacy problem. Internal infrastructure keeps data completely isolated within the company network. However, this isolation demands strict technical precision to maintain. Businesses must manage complex hardware setups and handle intricate model updates. They also apply deep technical logic to optimize these systems for specific domain workloads. Just as search engine marketing campaigns require constant adjustment to reach specific audiences, local deployments demand ongoing technical attention to remain effective. This tension between cloud convenience and local control forces companies to examine the specific financial constraints of their infrastructure.
Total Cost of Ownership Across Deployments
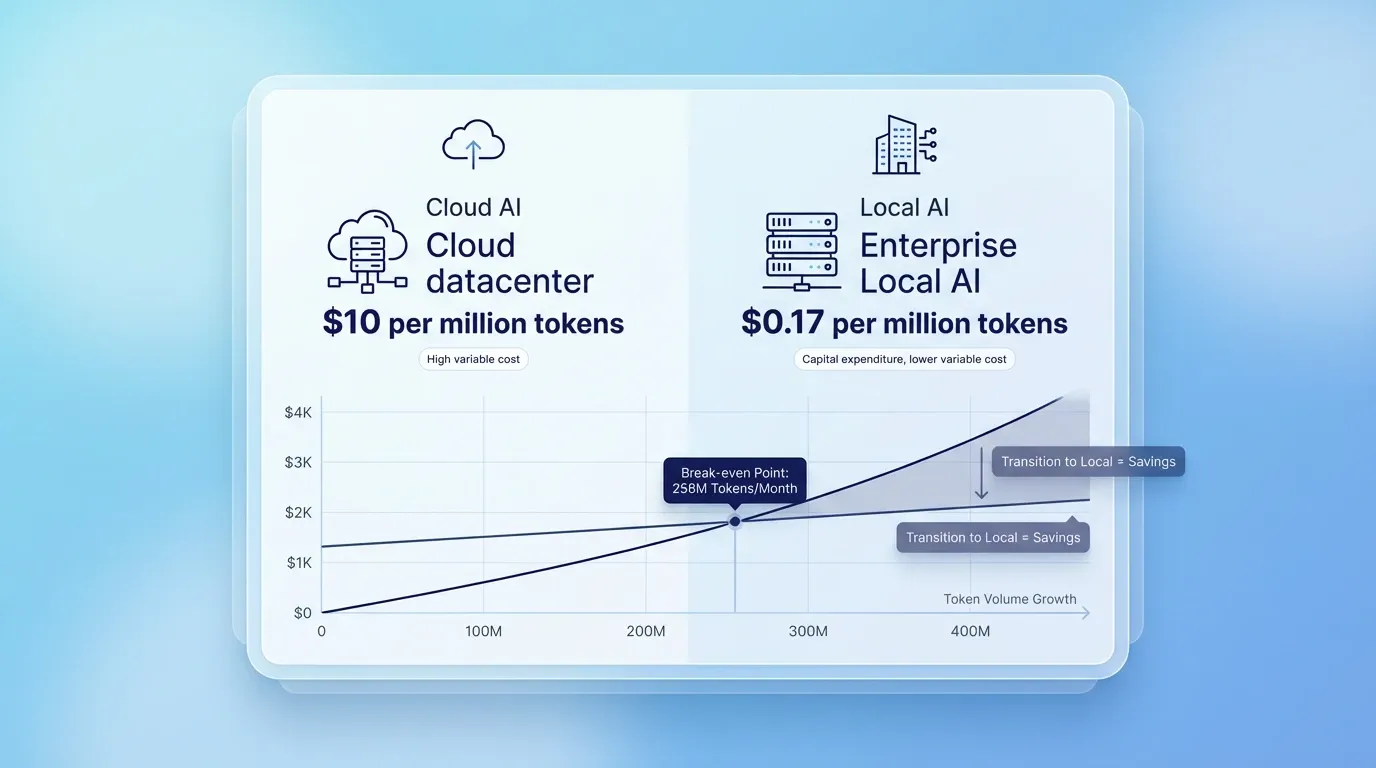
Companies must compare the variable token costs of cloud platforms against the large capital expenditures of local infrastructure when they evaluate an artificial intelligence api. Cloud providers charge for every token that passes through their endpoints. These variable costs scale directly with token volume. A high-traffic application can quickly generate an unsustainable monthly bill when businesses rely exclusively on an external ai inference service.
In contrast, local deployments require large upfront investments in graphics processing units and data center space. These physical servers incur ongoing electricity and maintenance expenses after installation. If an organization generates enough token traffic, local infrastructure eventually becomes the cheaper option. A self-hosted Llama 3.3 70B model costs just $0.17 per million tokens compared to the ten-dollar price tag for the same volume through GPT-4o. Analysts calculate that local infrastructure breaks even against cloud endpoints at approximately 256 million tokens monthly. Financial models require strict precision to capture all hidden expenses across both deployment paths. Companies apply financial logic to evaluate several critical cost factors before they approve an infrastructure budget:
-
Hardware depreciation rates
-
Cooling and electricity consumption
-
Software licensing fees
-
Specialized technical salaries
Organizations discover savings over time when they transition from cloud dependencies to local infrastructure. Just as one agency moved from invisible to impactful operations when they internalized their core processes, enterprises can stabilize their expansion costs when they own their compute resources. After companies resolve these complex financial equations, they must address the technical constraints that affect system responsiveness.
Network Latency Performance Bottlenecks
Cloud architectures often introduce severe performance issues that degrade the user experience during high-volume workloads. External endpoints rely on internet connectivity to transmit queries and receive responses. This geographical distance between the application server and the artificial intelligence api templates creates network delays. API latency increases with network delay, server processing time, and database queries. Generic horizontal cloud models must serve thousands of customers simultaneously.
Cloud providers impose strict rate limit mechanisms to manage this high traffic. For example, Azure OpenAI rate limits enforce specific tokens and requests per minute to prevent system overload. If an enterprise application exceeds these predefined thresholds, the provider blocks subsequent requests and causes immediate service outages. Local models solve these latency and rate limit problems. Internal servers process requests directly on the local network. This close proximity eliminates internet transmission delays and provides consistent response times. Companies can configure these customized vertical local models to prioritize critical workloads and bypass arbitrary rate limits. Businesses need architectural precision to build these responsive systems. They use strict routing logic to send time-sensitive queries to local hardware while they offload low-priority background tasks to external services. This hybrid routing ensures applications remain responsive under heavy loads. Organizations solve these performance bottlenecks when they build local architectures, and these internal systems also protect sensitive user information from external exposure.
Regulatory Compliance and Data Sovereignty
Organizations prioritize data sovereignty when they integrate an artificial intelligence api into their core products because strict regulatory frameworks require this protection. These organizations transmit sensitive information across external networks when cloud providers require this processing. This transmission creates immediate compliance risks because organizations lose direct control over their proprietary datasets. Organizations map data flows and identify potential exposure points across the entire system architecture to prevent these risks. They recognize that external vendors introduce supply chain vulnerabilities that compromise enterprise security when processing corporate data. A single compromised vendor exposes clients to legal consequences and reduces public trust. Organizations build sovereign infrastructure to protect customer privacy and keep data entirely within the corporate perimeter. Local deployments ensure that sensitive information never leaves the internal network. This isolation requires high precision to execute correctly, but it guarantees complete data control. Just as nonprofit organizations optimize digital presence to protect donor data while reaching wider audiences, enterprises optimize their infrastructure to protect user information while scaling their services. These strict data sovereignty requirements expose the inherent vulnerabilities that external vendors introduce when they provide machine learning capabilities.
Third-Party Supply Chain Breaches And API Templates
External endpoints expose sensitive user information to supply chain breaches. Organizations entrust external vendors with proprietary data when they connect their applications to a commercial machine learning platform. This reliance creates a security vulnerability that internal security teams cannot directly monitor or control. Even industry leaders struggle to maintain perfect perimeter defense against sophisticated attacks. For instance, a major OpenAI security breach exposed user names, email addresses, and approximate locations to unauthorized individuals. Such incidents demonstrate that third-party platforms experience data protection failures. Organizations evaluate these security risks before they transmit confidential customer records across the internet. Security teams manage these vulnerabilities when they audit external vendors. Organizations protect corporate assets when they examine how regulatory bodies penalize these external data breaches.
Specialized Compliance Requirements
Strict legal frameworks heavily penalize organizations that route regulated data through unapproved external endpoints. The Health Insurance Portability and Accountability Act and General Data Protection Regulation guidelines mandate strict control over personal information. Healthcare providers face financial penalties if they expose patient records to unauthorized external servers. For example, using public Large Language Models such as ChatGPT without a Business Associate Agreement triggers HIPAA violations. Compliance officers apply strict legal logic to prevent these infrastructure mistakes. They require engineering teams to implement isolated local models when handling protected health information or confidential financial records. Developers use artificial intelligence api templates to standardize these secure local deployments across different enterprise departments. Compliant local systems force companies to confront technical hurdles and engineering resource shortages.
Technical Talent Gap
Organizations require specialized engineering teams to maintain sovereign infrastructure, and these professionals currently dominate the most competitive hiring markets. Standard backend developers easily integrate external cloud endpoints into existing applications. They do not need advanced programming skills to send requests to an artificial intelligence api and format the returning data. Conversely, local deployments demand deep expertise in machine learning operations. Organizations hire Machine Learning Operations engineers to configure hardware, optimize model weights, and monitor system degradation. The technology sector faces a talent shortage that complicates hiring these experts. Analysts project that the United States tech sector will face a shortage of 1.2 million software engineers by 2026. This scarcity drives compensation packages to unprecedented levels. Currently, MLOps engineer salaries average $158,000 and often reach $220,000. Organizations execute several strategies to build a successful local infrastructure team. They audit existing internal talent for potential machine learning transition paths. They also allocate specific budget increases for specialized engineering compensation and partner with external consulting firms to bridge immediate technical knowledge gaps. Companies apply strict financial logic to justify these payroll expenses. They calculate whether the data privacy benefits of a local ai inference service outweigh the costs of hiring specialized talent. Just as charities use targeted digital outreach to maximize their limited resources, enterprises deploy their expensive engineering talent with high precision. This talent scarcity pushes organizations to design architectures that balance expensive local control with accessible cloud scalability.
Hybrid-by-Design Routing Framework
A hybrid infrastructure resolves the tension between expensive sovereign deployments and vulnerable cloud endpoints. Organizations achieve optimal performance when they divide their workloads across different computing environments. Engineering teams design routing gateways that evaluate every incoming request before the systems process it. These systems classify data based on specific security requirements. The router directs sensitive patient records or financial transactions to secure local models. Simultaneously, the router sends generic queries and low-priority tasks to a cheaper external ai inference service. This architecture allows organizations to maintain data compliance without purchasing hardware clusters for every computing task. Developers use artificial intelligence api templates to standardize the connection protocols between these internal and external systems. The industry rapidly adopts this balanced approach to manage long-term scaling costs. Researchers project that hybrid and edge deployments will capture 43.5% of the market share by 2030. This dual-path methodology gives organizations the precision they need to optimize their infrastructure budgets. Organizations protect their proprietary information while still using the computational power of commercial cloud providers. This strategic routing framework provides a sustainable path for enterprises when they scale complex machine learning capabilities.
Conclusion
To summarize, evaluating infrastructure requirements reveals that no universal artificial intelligence api deployment model perfectly fits all functional workloads. Companies protect long-term product viability when they carefully balance immediate deployment convenience against ongoing operational costs and strict data sovereignty requirements. As enterprise architecture evolves, organizations will increasingly adopt a strategic, hybrid-by-design approach that intelligently uses cloud scalability for standard tasks and securely isolates sensitive user data within local infrastructure. Similar to how content creation systems streamline operations, hybrid networks optimize processing efficiency. Reviewing current data classification policies and mapping current workloads helps determine which processes require local isolation.